
刷题笔记-二叉树
刷题笔记-二叉树
- C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树,所以map、set的增删操作时间时间复杂度是logn
- unordered_map、unordered_map底层实现是哈希表
- 顺序存储完全二叉树: 如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2
- 深度优先遍历(前中后序)一般通过递归实现, 也可通过栈使用非递归实现
- 广度优先遍历(层次遍历)一般通过队列实现
二叉树创建
1 | public TreeNode CreateTree(Integer[] c) { |
深度优先遍历(递归)
前序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
ArrayList<Integer> res = new ArrayList<>();
traversal(root,res);
return res;
}
void traversal(TreeNode cur,List<Integer> res){
if(cur==null){
return;
}
res.add(cur.val);
traversal(cur.left,res);
traversal(cur.right,res);
}
}中序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> res = new ArrayList<>();
traversal(root,res);
return res;
}
void traversal(TreeNode cur,List<Integer> res){
if(cur==null){
return;
}
traversal(cur.left,res);
res.add(cur.val);
traversal(cur.right,res);
}
}后序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
ArrayList<Integer> res = new ArrayList<>();
traversal(root,res);
return res;
}
void traversal(TreeNode cur,List<Integer> res){
if(cur==null){
return;
}
traversal(cur.left,res);
traversal(cur.right,res);
res.add(cur.val);
}
}
深度优先遍历(非递归, 利用栈)
前序
较为简单, 因为对每一个节点的孩子来说, 他都是根节点, 在访问到它时, 直接将他的值放入数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public List<Integer> preorderTraversal(TreeNode root) {
ArrayList<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
result.add(node.val);
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
return result;
}中序
较前序复杂, 因为访问到一个节点时, 需先放入栈中, 直到它的左子树为空, 才弹出将它的值放入数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
if (cur != null) {
stack.push(cur);
cur = cur.left;
} else {
cur = stack.pop();
result.add(cur.val);
cur = cur.right;
}
}
return result;
}后序
利用一个规律–根右左的遍历结果反转一下就是后序遍历结果
为什么这样做呢, 因为这样跟前序一样简单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public List<Integer> postorderTraversal(TreeNode root) {
ArrayList<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
result.add(node.val);
if (node.left != null) {
stack.push(node.left);
}
if (node.right != null) {
stack.push(node.right);
}
}
Collections.reverse(result);
return result;
}
深度优先遍历一致性代码(非递归)
1 | public List<Integer> postorderTraversal(TreeNode root) { |
其他遍历顺序只需调整一下注释部分的顺序
广度优先遍历
1 | public List<List<Integer>> levelOrder(TreeNode root) { |
广度优先遍历(返回一维数组, 如果节点没有左孩子或右孩子, 为null)
1 | public ArrayList<Integer> levelOrder(TreeNode root) { |
1 | from collections import deque |
貌似和上边的Java代码效果一样…

最底层 最左边 节点的值
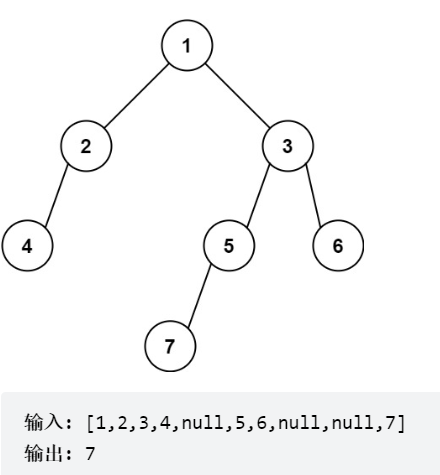
1 | public int findBottomLeftValue(TreeNode root) { |
队列广度遍历,先放右孩子,保证最后出来是最左
1 | int max = Integer.MIN_VALUE; |
深度搜索+递归, 一条路行到黑, 只要不是叶子节点, 就递归左 右, 碰到叶子节点再比较深度, 由于同一层次最左边的值先赋值给res, 右边深度相等, 不会赋值.
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Announcement
双 手 合 十 成 为 自 己 的 神, 自 己 所 信 念 的 即 是 信 仰

微信号:zq2551856565
QQ号:2551856565