
通过RSSHub订阅学院通知
通过RSSHub订阅学院通知
今天看到以为up主在介绍RSSHub, 遂入坑, 上午在了解RSS, 并搭建了RSSHub, 下午费了九牛二虎之力终于给学院写了个RSS订阅(只怪自己js学的不够通透)
大连理工大学软件学院(新) (dlut.edu.cn)RSS订阅地址: https://rss.zaqai.com/ssdut
路由: 默认是本科生通知, 即https://rss.zaqai.com/ssdut和https://rss.zaqai.com/ssdut/bkstz等价, 对应于本科生通知-大连理工大学软件学院(新) (dlut.edu.cn)
还有学院通知: https://rss.zaqai.com/ssdut/xytz, 对应于学院通知-大连理工大学软件学院(新) (dlut.edu.cn)
其他的通知对我来说用处不大, 所以没有适配, 大体上差不多, 只需要更改一些jquery选择器的东西
RSSHub介绍

万物皆可RSS, 其实就是给你提供一个大体框架, 具体爬取哪些元素要你自己写
原理就是当你访问RSSHub, 它会根据路由去请求指定的资源, 并转换为RSS格式
RSSHub搭建
部署 | RSSHub讲的很详细了, 虽然有服务器, 不过我还是推荐Vercel托管(我看的视频就是讲这个的), 直接域名cname到它提供的域名就行了. 但是有一点, github仓库里的代码改了之后, 它会自动重新部署, 但是好像并没有改变.
为没有适配RSS的网站适配RSS
只需修改两个文件:
RSSHub目录\lib\router.js
1
2
3
4// 大连理工大学
router.get('/dut/:subsite/:type', lazyloadRouteHandler('./routes/universities/dut/index'));
router.get('/ssdut/:type?', require('./routes/universities/dut/ssdut'));增加一个ssdut的路由, :type?为可选参数
RSSHub目录\lib\routes\universities\dut\ssdut.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104const got = require('@/utils/got');
const cheerio = require('cheerio');
const url = require('url');
// 域名
const host = 'http://ssdut.dlut.edu.cn';
// 分类
const map = {
bkstz: '/index/bkstz.htm',
xytz: '/index/xytz.htm',
};
module.exports = async (ctx) => {
// 这里获取到传入的参数,也就是 /ncu/jwc/:type? 中的 type
// 通过 || 来实现设置一个默认值
const type = ctx.params.type || 'bkstz';
// 要抓取的网址
const link = host + map[type] ;
// 获取列表页,也就是发出请求,来获得这个文章列表页
const response = await got({
method: 'get', // 请求的方法是 get,这里一般都是 get
url: link, // 请求的链接,也就是文章列表页
});
// 用 cheerio 来把请求回来的数据转成 DOM,方便操作
const $ = cheerio.load(response.data);
// 提取列表项
const urlList = $('.c_hzjl_list1') // 筛选出所有 class=".c_hzjl_list1" 的内容
.find('a') // 找到所有 <a> 标签,也就是文章的链接
.slice(0, 20) // 获取 10 个,也可以把它调大一点,比如 15 个。最大的个数要看这个网页中有多少条
.map((i, e) => $(e).attr('href')) // 作为键值对来存储 <a> 标签们的 href 属性
.get();
// 要输出的文章内容保存到 out 中
const out = await Promise.all(
// 抓取操作放这里
urlList.map(async (itemUrl) => {
// 获取文章的完整链接
itemUrl = url.resolve(host+map[type] , itemUrl);
// 这里是使用 RSSHub 的缓存机制
const cache = await ctx.cache.get(itemUrl);
if (cache) {
return Promise.resolve(JSON.parse(cache));
}
// 获取列表项中的网页
const response = await got.get(itemUrl);
const $ = cheerio.load(response.data);
// single 就是一篇文章了,里面包括了标题、链接、内容和时间
const single = {
title: $('title').text(), // 提取标题
link: itemUrl, // 文章链接
description: $('.v_news_content') // 文章内容,并且用了个将文章的链接和图片转成完整路径的 replace() 方法
.html()
.replace(/src="\//g, `src="${url.resolve(host, '.')}`)
.replace(/href="\//g, `href="${url.resolve(host, '.')}`)
.trim(),
pubDate: new Date(
$('.mt_15, .mb_15, .mt_10, .mb_10')
.text()
.match(/[1-9][0-9]{3}年[0-9]{2}月[0-9]{2}日/).toString()
.match(/[1-9][0-9]{3}/)+'-'+
$('.mt_15, .mb_15, .mt_10, .mb_10')
.text()
.match(/[1-9][0-9]{3}年[0-9]{2}月[0-9]{2}日/).toString()
.match(/[0-9]{2}/g)[2]+'-'+
$('.mt_15, .mb_15, .mt_10, .mb_10')
.text()
.match(/[1-9][0-9]{3}年[0-9]{2}月[0-9]{2}日/).toString()
.match(/[0-9]{2}/g)[3]
).toUTCString(), // 将时间的文本文字转换成 Date 对象
};
// 设置缓存及时间
ctx.cache.set(itemUrl, JSON.stringify(single), 24 * 60 * 60);
// 输出一篇文章的所有信息
return Promise.resolve(single);
})
);
// 设置分类的标题
let info = '本科生通知';
if (type === 'xytz') {
info = '学院通知';
}
// 访问 RSS 链接时会输出的信息
ctx.state.data = {
title: '大工软院 - ' + info,
link: link,
description: '大工软院 - ' + info + ' ssdut.dlut.edu.cn',
item: out,
};
}
作用
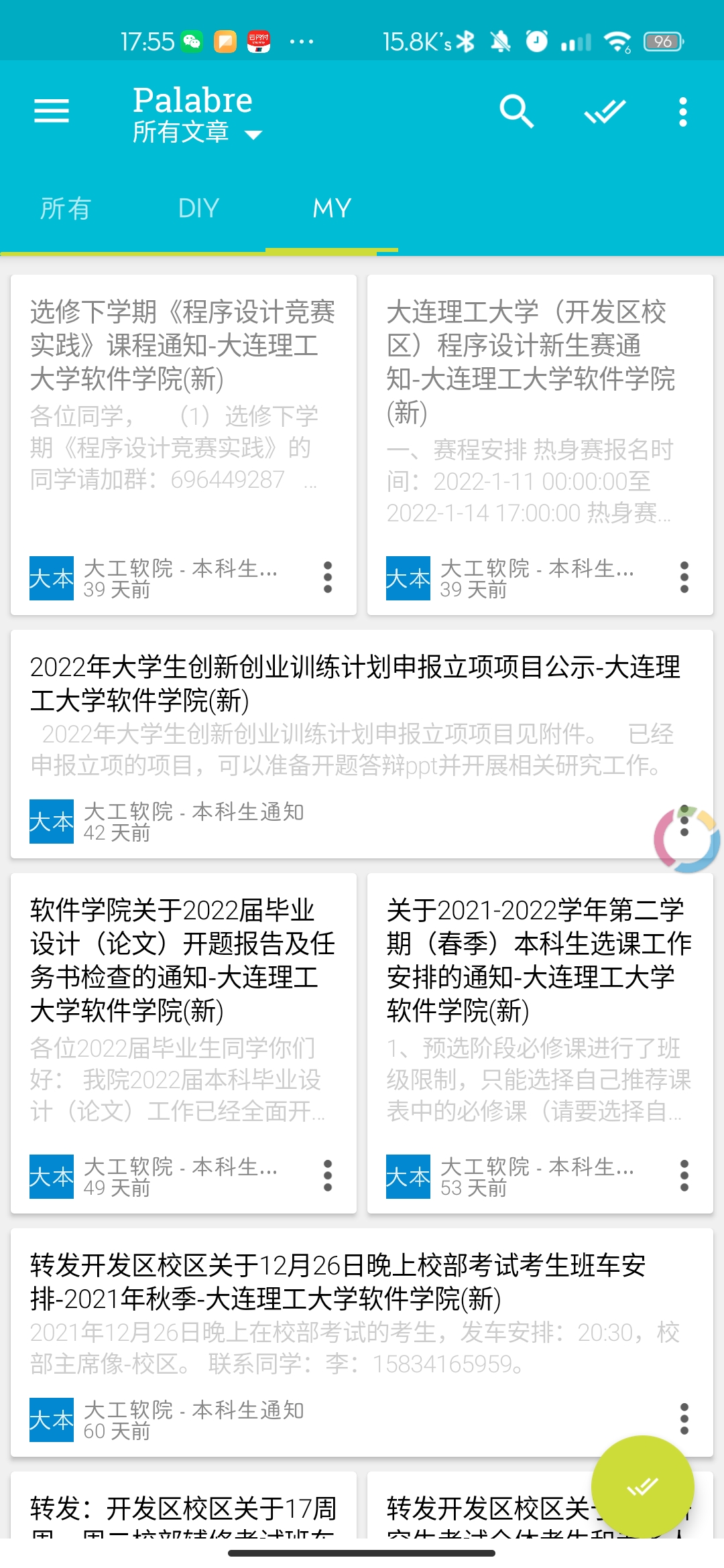
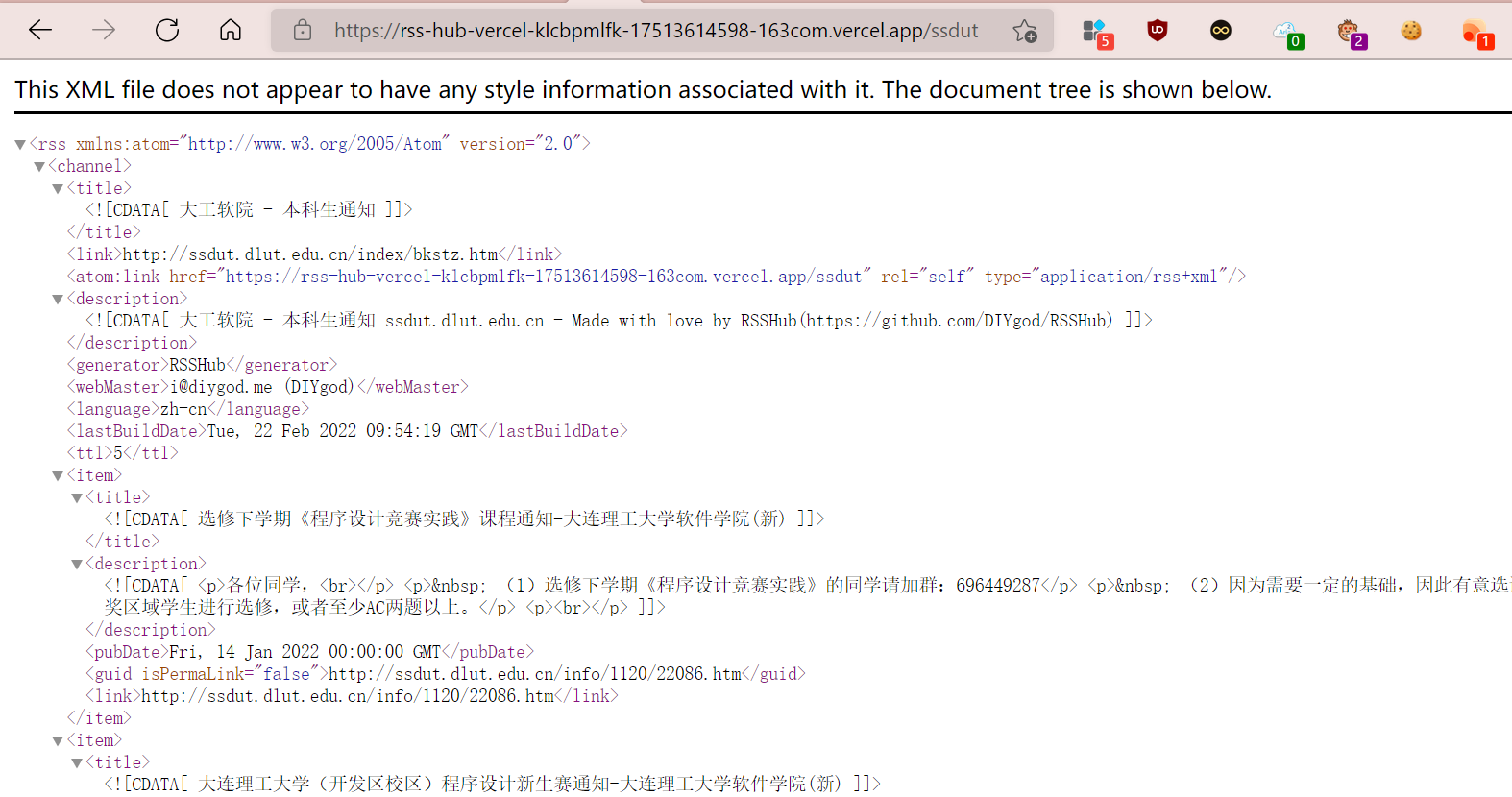
获取专属消息通知, 避免遗漏学院重要通知
效果
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Announcement
双 手 合 十 成 为 自 己 的 神, 自 己 所 信 念 的 即 是 信 仰

微信号:zq2551856565
QQ号:2551856565