java集合
一些遍历方法
迭代器遍历列表
1
2
3
4
5
| List<String> list=new ArrayList<String>();
Iterator<String> it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
|
遍历map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| Map<String, String> map = new HashMap<String, String>();
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
|
Queue
LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用
//add()和remove()方法在失败的时候会抛出异常(不推荐)
一般情况下 Queue 的实现类都不允许添加 null 元素, 防止和poll() peek()中返回的null混淆
1
2
3
4
5
6
7
8
9
10
11
12
13
|
offer(element);
poll();
element();
peek();
put(e);
take();
|
环形队列
- 约定front指向队列的第一个元素,也就是说data[front]就是队头数据,front初始值为0。
- 约定rear指向队列的最后一个元素的后一个位置,也就是说data[rear-1]就是队尾数据,rear初始值为0。
- 队列满的条件是:***( rear+1 )% maxSize == front***
- 队列空的条件是:rear == front
- 队列中的元素个数为:***( rear - front + maxsize) % maxSize***
- 因为rear指向队尾的后面一个位置,这个位置就不能存数据,因此有效数据只有maxSize-1个
Stack
基于Vector实现的LIFO的栈
1
2
3
4
5
6
7
8
| import java.util.Stack;
Stack<Type> stacks = new Stack<>();
push(element);
pop();
peek();
search(element);
boolean empty();
|
Vector
一种线程安全的List实现;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| Vector<Type> vector = new Vector<>();
add(element) - 向向量(vector)添加元素
add(index, element) - 将元素添加到指定位置
addAll(vector) - 将向量(vector)的所有元素添加到另一个向量(vector)
addElement(obj)
setElementAt(E obj, int index)
insertElementAt(E obj, int index)
get(index) - 返回由索引指定的元素
firstElement()
lastElement()
elementAt(int index)
int indexOf(E obj)
int indexOf(E obj, int index)
int lastindexOf(E obj)
int lastIndexOf(E obj, int index)
void removeRange(int fromIndex, int toIndex)
void removeElement(E obj)
remove(index) - 从指定位置删除元素
removeAll() - 删除所有元素
clear() - 删除所有元素。它比removeAll()更高效
void removeAllElement();
void removeElementAt(int index)
set() 更改向量的元素
size() 返回向量的大小
toArray() 将向量转换为数组
toString() 将向量转换为字符串
contains() 在向量中搜索指定的元素并返回一个布尔值
Enumeration<String> elements = vector.elements();
while (elements.hasMoreElements()) {
System.out.println(elements.nextElement());
}
Iterator<String> it = vector.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
|
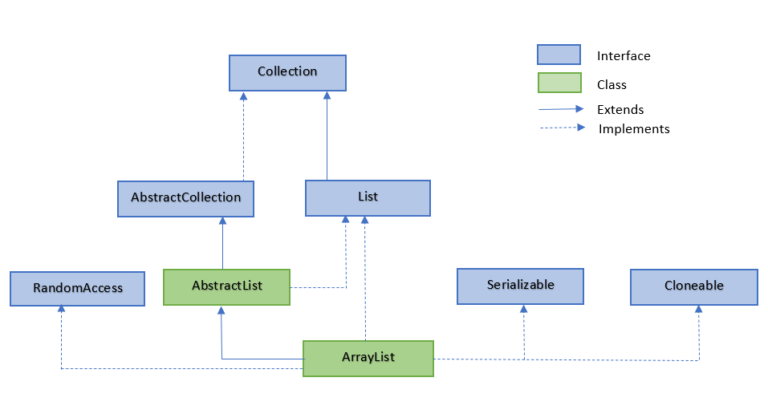
ArrayList
底层基于数组, 访问O(1), 插入删除O(n), 内存开销较LinkedList小
线程不安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import java.util.ArrayList;
ArrayList<E> l =new ArrayList<>();
public boolean add(e);
public void add(index, e);
public boolean remove(object)
public E remove(int index)
public E set(int index, E element)
public E get(index index)
public int size()
void clear()
boolean contains(Object o)
int indexOf(Object o)
boolean isEmpty()
Iterator<E> iterator()
Object[] toArray()
Collections.sort(l);
|
LinkedList
底层基于链表, 插入删除O(1), 访问O(n), 内存开销大
线程不安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
boolean add(E e)
void add(int index, E element)
void addFirst(E e)
void addLast(E e)
boolean offer(E e)
boolean offerFirst(E e)
boolean contains(Object o)
E element()
E get(int index)
E getFirst()
E getLast()
E peek()
E peekFirst()
E poll()
E pop()
void push(E e)
int indexOf(Object o)
int lastIndexOf(Object o)
|
Hashtable
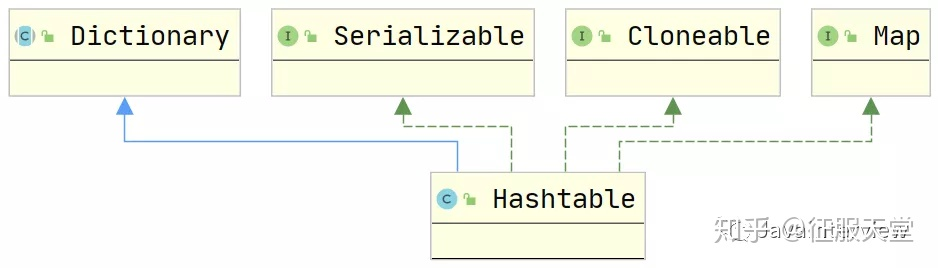
是一个散列表, 存储的是键值对映射
操作基本上和HashMap一样, 不同的是HashTable是同步的, 线程安全, 也就意味着效率比HashMap低
不允许键或值为null
底层数组长度可以为任意值,这就造成了hash算法散射不均匀,容易造成hash冲突,默认为11
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| void clear( )
boolean contains(Object value)
boolean containsKey(Object key)
boolean containsValue(Object value)
Enumeration elements( )
Object get(Object key)
boolean isEmpty( )
Enumeration keys( )
Object put(Object key, Object value)
Object remove(Object key)
int size( )
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
integ = (Integer)entry.getValue();
}
|
HashMap
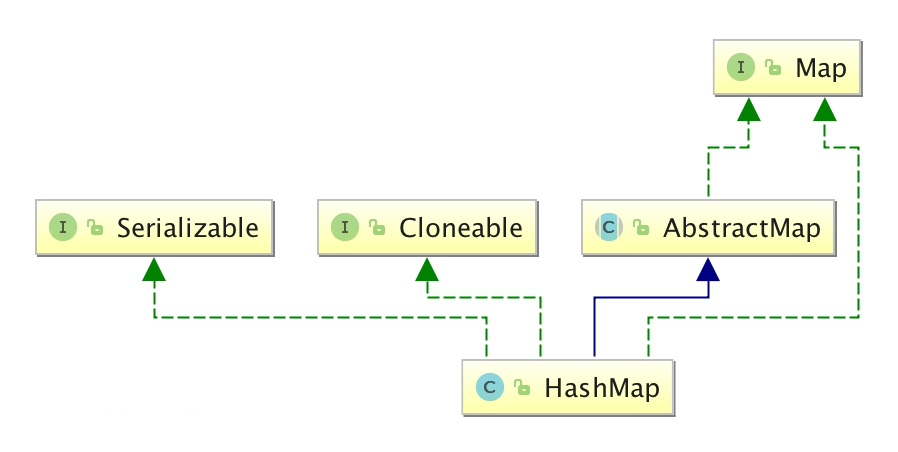
允许有一个键为null,允许多个值为null
底层数组长度必须为2的幂,这样做是为了hash准备,默认为16
没有同步, 线程不安全,如需线程安全可使用ConcurrentHashMap ,HashTable并发性不如 ConcurrentHashMap,因为 ConcurrentHashMap 引入了分段锁。Hashtable 不建议在新代码中使用
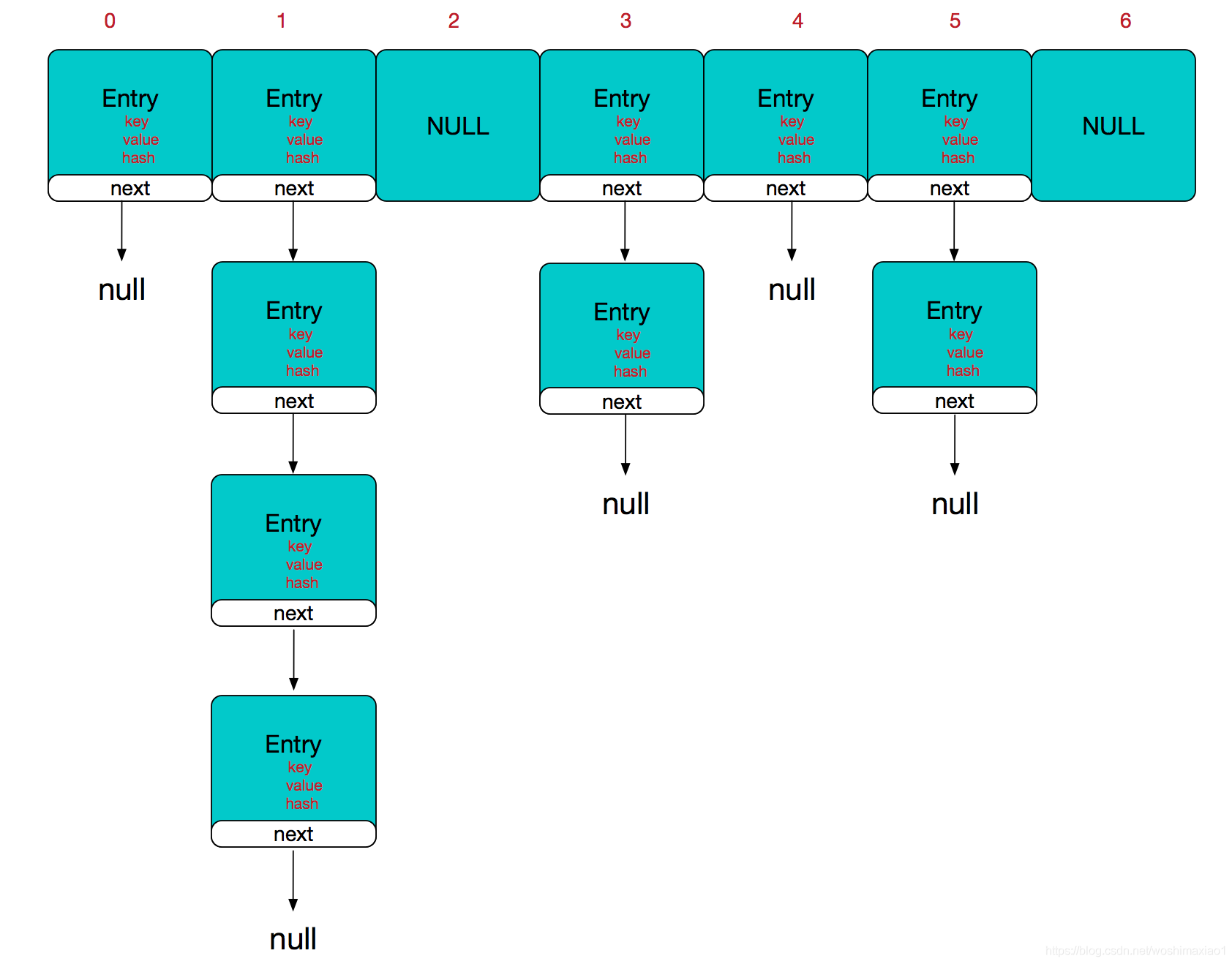
由数组+链表组成, 数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的
当两个key均被hash到数组同一个位置时,会在该位置挂起一个链表
java8之后,当链表长度达到8时,会将链表转换为红黑树,遍历红黑树复杂度为O(logn),由于链表(O(n))
满了之后,数组会扩容值原来的二倍,在jdk1.7及之前,需要rehash,重新计算每个元素位置,可能导致原来冲突的位置不再冲突。
在jdk1.8之后,做了巧妙的优化,如在大小为16的时候,5和21会被hash到同一个位置,扩容后大小为32,5还在5,21变为21位置。对比5(0101)和21(10101),只是前面多了个1,也就是变为2倍。
所以只用将key和11111做与操作就知道扩容后的位置,如0101&11111=0101(5还是5),10101&11111=10101(21)
如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
TreeMap
红黑树对所有的key进行排序
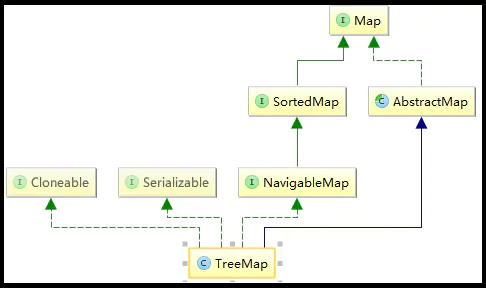
- 不允许出现重复的key;
- 可以插入null键,null值;
- 可以对元素进行排序;
- 无序集合(插入和遍历顺序不一致)
红黑树
红黑树,即红颜色和黑颜色并存的二叉树,插入的元素节点会被赋为红色或者黑色,待所有元素插入完成后就形成了一颗完整的红黑树, 底层是二叉查找树
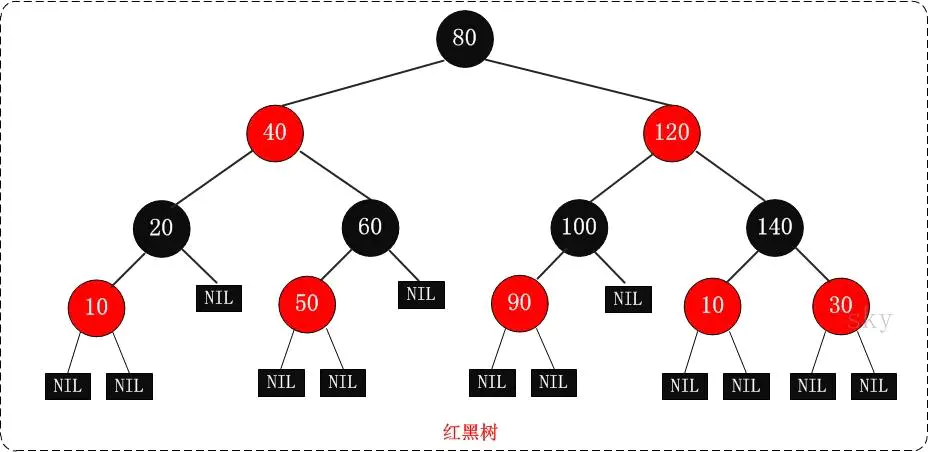
- 树中每个节点必须是有颜色的,要么红色,要么黑色;
- 树中的根节点必须是黑色的;
- 树中的叶节点必须是黑色的,也就是树尾的NIL节点或者为null的节点;
- 树中任意一个节点如果是红色的,那么它的两个子节点一点是黑色的;
- 任意节点到叶节点(树最下面一个节点)的每一条路径所包含的黑色节点数目一定相同
Set
唯一性的比较过程:
存储元素首先会使用hash()算法函数生成一个int类型hashCode散列值,然后已经的所存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象;
如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;
如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
HashSet采用哈希算法保证不重复,底层用数组存储数据。默认初始化容量16,加载因子0.75。
LinkedHashMap
HashMap 的一个子类,保存了记录的插入顺序,在用 Iterator 遍历LinkedHashMap 时,先得到的记录肯定是先插入的。也可以根据访问顺序排序。而HashMap 在遍历时不能保证顺序
LinkedHashSet
继承自HashSet、又基于 LinkedHashMap 来实现的,元素顺序是可以保证的
覆盖hashCode()方法的原则:
1、一定要让那些我们认为相同的对象返回相同的hashCode值
2、尽量让那些我们认为不同的对象返回不同的hashCode值,否则,就会增加冲突的概率。
3、尽量的让hashCode值散列开(两值用异或运算可使结果的范围更广)

